初心者向けGoogle Search Console【第2回】「クロール状況を把握し、正しくクローリングさせよう」

前回の「初心者向けGoogle Search Console」では、Google Search Consoleの導入方法と基本的な情報をご紹介させていただきました。
今回からは、「Google Search Consoleでできること」について機能の詳細をひとつひとつご紹介していきます。
今回は、「クロール」に関する3つの便利な機能をご紹介します。
クロールとは
クロールとは、「クローラー」と呼ばれるロボットが、インターネット上のWebページをひとつひとつ巡回し、情報を収集することをいいます。
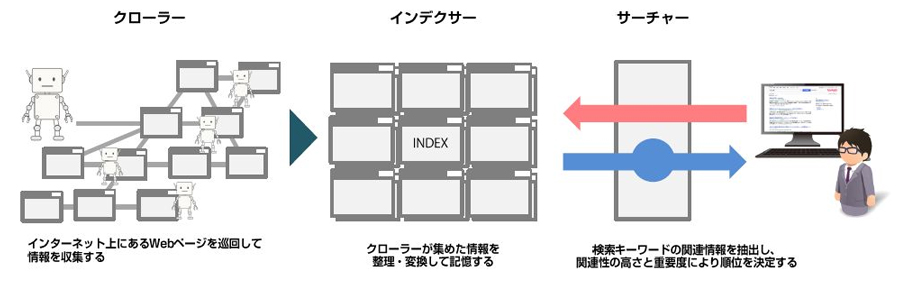
クローラーや検索エンジンの仕組みについてはこちらをご覧ください。
自分のWebサイトを検索結果に表示させるためには、まずクローラーにクロールされること(クローリング)が必要です。
Google Search Consoleでは、自分のWebサイトのクロール状況を把握し、正しくクローリングされているかどうかを確認することができます。
【できること その1】クロールエラーのチェック
クロールに問題がある場合、デバイス別にエラーの内容を確認することができます。
エラーとなっているURLをクリックすると、エラー内容の詳細と対処方法が表示されるため、個別のページごとにエラー状況を確認し、適切な対応を行なうことができます。
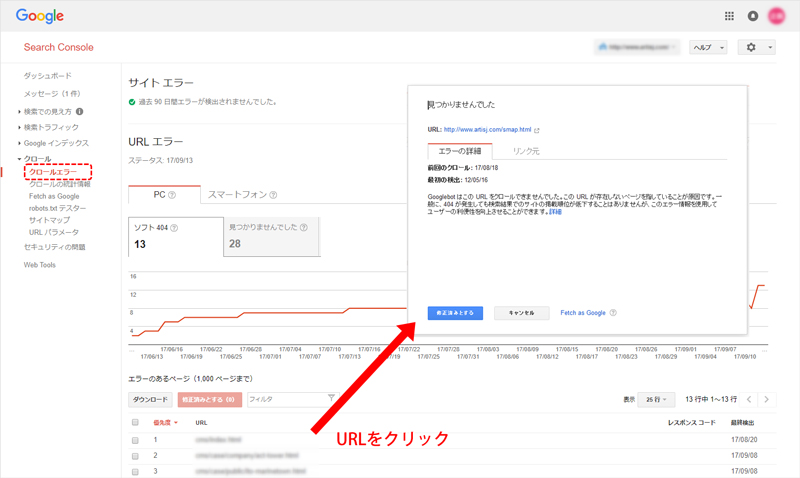
【手順】クロール→クロールエラー
表示される主なエラーの種類について解説します。
サーバーエラー
サーバの応答が遅すぎるか、クローラーによるサイトへのアクセスがブロックされている状態をいいます。
対処方法は以下の通りです。
- 動的ページへのリクエストに伴う過剰なページ読み込みを減らす
- ホスティング サーバの停止、過負荷、設定ミスが起きていないことを確認する
- 誤って Google のクローラーがブロックされていないことを確認する
- 検索エンジンによるサイトのクロールとインデックス登録を適切に管理する
アクセス拒否のエラー
サーバで認証が必須となっているか、クローラーによるサイトへのアクセスがブロックされている状態をいいます。
対処方法は以下の通りです。
- robots.txtファイルが想定どおりに動作しており、Googleのアクセスをブロックしていないかどうか確認する(後述)
- Fetch as Googleを使用して、サイトが Google からどのように認識されるかを確認する(後述)
- Googleインデックス>ブロックされたリソースから確認→robots.txtでブロックの解除を行なう(詳しくはこちら)
404エラー
URL が存在しないページを指しています。
404 エラーのほとんどは、検索結果でのランキングに影響を及ぼすことはないため、エラーを無視しても問題はありませんが、次の点を確認し対処することをおすすめします。
- ページが削除されており、代わりのページや同じようなページがない場合は、404 を返すようにする
- 無効なリンクが公開されている場所(リンク元)を確認し、他のサイトからのリンクでスペルミス等がある場合は、301リダイレクトで対応する
【できること その2】クロールから除外したいコンテンツの指定
クロールさせたくないコンテンツを指定するには、サーバ上にある「robots.txt」というファイルに記述を追記する必要があります。
Google Search Consoleでは、robots.txtの記述テストとGoogleへのリクエスト送信を行なうことができます。

【手順】クロール→robots.txt テスター
自分のWebサイトにすでにrobots.txtが設置されている場合、自動的にrobots.txtの内容が表示されます。
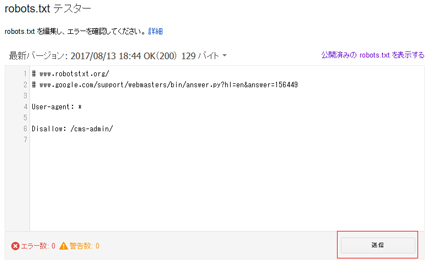
まずは、「エラー数」「警告数」が0になっていることを確認します。
robots.txtの記述変更手順について解説します。
robots.txtの記述テスト
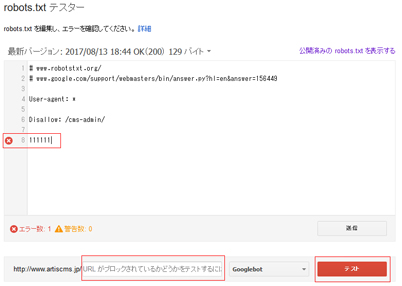
robots.txtの内容を画面上で修正し、構文に問題がないかをテストすることができます。(この段階ではまだ、実際に設置されているrobots.txtの内容は更新されません。)
構文に問題がある場合は、画面上にエラーや警告のマークが表示されます。
画面下部に設定したURLを入力し、テストボタンをクリックして「ブロック済み」と表示されればテスト完了です。
robots.txtを公開し、Googleにリクエストを送る
テストが完了したら、右下の送信ボタンをクリックします。
送信ボタン
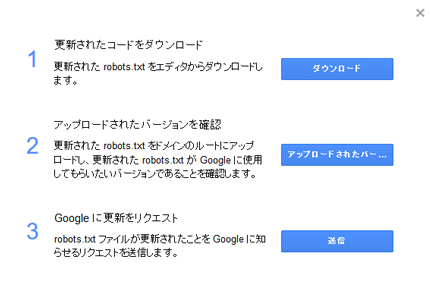
ポップアップ画面
すると上記のようなポップアップ画面が開くので、あとは1~3の手順に従って
| robots.txtをダウンロードし、ローカルに保存 ↓ 公開サーバにアップ後、「アップロードされたバージョンを確認」ボタンから、正しいrobots.txtが公開されているかを確認 ↓ Googleに更新リクエストを「送信」 |
すれば、作業完了です。
【できること その3】再クロールの申請
前述の通り、自分のWebサイトを検索結果に表示させるためには、クローリングされなければいけません。
Google Search Consoleでは、新しくWebサイトを公開したり、ページを追加したりする場合に「Fetch as Google」という機能を使って、Googleへクロールの申請をすることができます。
Fetch as Googleとは?
Fetch as Googleとは、Googleが行うURLのクロールやレンダリングの方法をテストすることができる機能です。
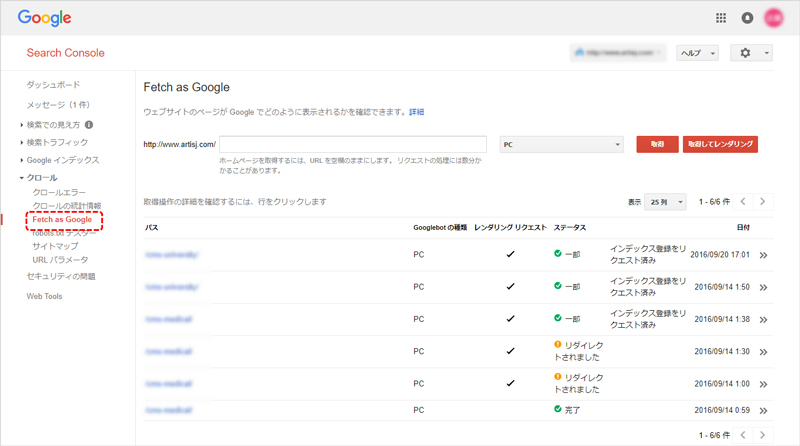
【手順】クロール→Fetch as Google
URLの再クロールを申請する方法
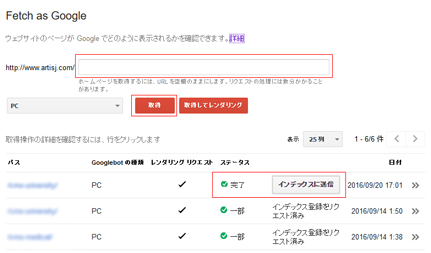
クロールの申請をしたいURLを入力し、「取得」ボタンをクリックします。
※入力欄を空欄にしたまま「取得」をクリックすると、サイト全体がクロールされます。
データの取得が完了すると、ステータスが「完了」に変わり、「インデックスを送信する」ボタンが表示されます。
完了以外のステータスが表示された場合は、Search Console ヘルプに記載されている対処方法をご確認ください。
| ステータス | 取得内容 |
|---|---|
| 完了 | 正常にページをクロールし、すべてのリソースを取得できた |
| 一部完了 | ページは取得できたが、その中に含まれる画像等リソースの一部が取得できない |
| リダイレクトされました | リダイレクト設定がされていて、リダイレクト先にアクセスできない |
| 見つかりませんでした | ページが存在しない |
| アクセスできません | ページにアクセスする権限がない |
続けて「インデックスに送信」をクリックし、送信方法を選択します。
▼このURLのみをクロールする
特定のURLだけ指定する場合に使用(1ヵ月の上限は500件)
▼このURLと直接リンクをクロールする
指定したURLとそのページからの全てのリンクを対象とする場合に使用(1ヵ月月の上限は10件)
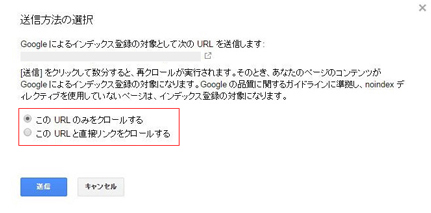
送信方法の選択画面
最後に「送信」ボタンを押せば、再クロール申請完了です。
※再クロール後に、検索結果ページへ反映される速度はサイトによって異なります。
レンダリング結果を確認する方法
クローラーからのサイトの見え方を確認することができます。
レンダリングの確認をしたいURLを入力し、「取得してレンダリング」をクリックします。
(デバイスを変更すれば、スマホからの見た目も確認することができます。)
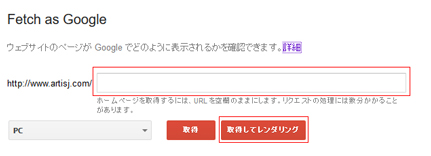
ステータスが「完了」に変わったら、該当の項目をクリックし、「レンダリングタブ」を開きます。
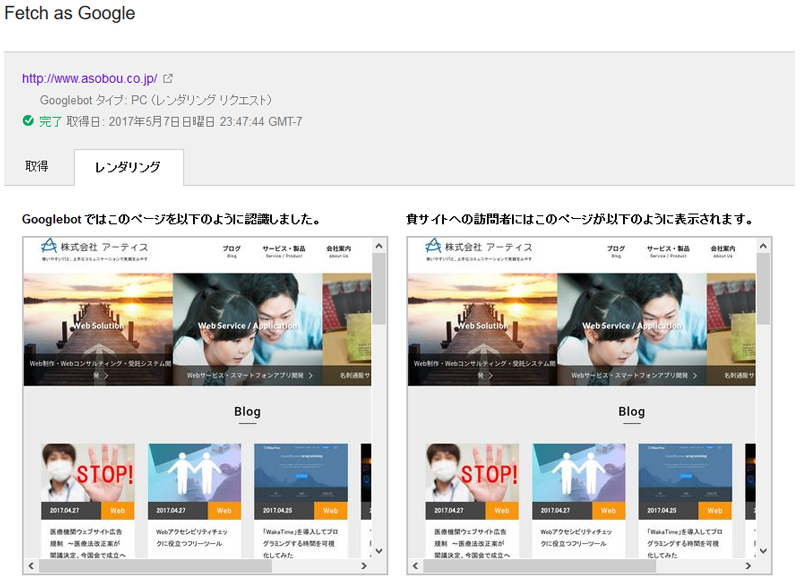
このように、クローラーから見たサイトのイメージとユーザがブラウザから見るサイトのイメージが表示され、Webサイトの情報が正確にクローラーに伝えられているかを確認することができます。
また、クロールにエラーがあった場合は、その原因を確認することもできます。
さいごに
今回は、SEOを行なう上で欠かせない「クロール」に関する機能を紹介させていただきました。
何もせずにWebサイトを放置していたとしても、Googleはいつかリンクを辿ってクロールをしてくれますが、サイトによってその速度は異なるため、いつクローラーがやってくるかはわかりません。
いつくるかわからないクローラーを待つのではなく、より早く確実に効果を出すためにも、Google Search Consoleの便利な機能を使って、クロールの申請やエラーの確認をこまめに行なっていくと良いでしょう。
次回は、クローラーが収集してきたWebサイトの情報をGoogleに登録する「インデックス」という仕組みについて、Google Search Consoleでできる対策をご紹介します。
この記事を書いた人

- 創造性を最大限に発揮するとともに、インターネットに代表されるITを活用し、みんなの生活が便利で、豊かで、楽しいものになるようなサービスやコンテンツを考え、創り出し提供しています。
この執筆者の最新記事
関連記事





最新記事





FOLLOW US
最新の情報をお届けします
- facebookでフォロー
- Twitterでフォロー
- Feedlyでフォロー