アウトライン化されたaiデータから、できる限りテキスト情報を取り出す方法

「パンフレットの情報をもとにwebページを構築しなくてはならないが、提供いただいたイラレデータがアウトライン化されていて、テキストがコピーできない!」
私がエディターとして仕事をしているとき、まれに遭遇する事態です。
データがアウトライン化されていると、テキスト情報を抽出(コピー)することができません。
テキストを手入力することもできますが、タイプミスの恐れもあり、量が膨大なときは手入力自体なかなか大変な作業で…。
こんなときに、最後の切札として試みる「アウトライン化されたイラレデータからテキスト情報を取り出す方法」があります。今回はその方法をご紹介します!
※今回ご紹介する機能を使用するには「Adobe Acrobat Pro DC」のインストールが必要です。「Adobe Acrobat Standard DC」には対応しておりませんのでご注意ください。そもそも、アウトライン化とは?
平たく言うと、文字データ(フォントデータ)を図形データに変換することを指し、印刷業界では必須の工程です。
なぜなら、見せたいフォントを文字データのままにすると、パソコンの環境によっては別のフォントに変換される可能性があるからです。
そのため文字データをアウトライン化し、図形データとして表示させることが必要なのです。

アウトライン化されたデータの完全復元は基本的にできない
データを一度アウトライン化してしまうと、フォントは図形として認識されるため、コピー&ペーストができなくなります。
アウトライン化されたデータを完全に復元することは不可能なため、データと同じ内容を他の箇所に入力したい場合は文字を手入力で打ち換えるという手間が発生してしまいます。
しかし、アウトライン化されたイラレデータからできるだけ文字を抽出できる秘策があるのです。
Illustratorアウトラインデータのテキストを抽出する方法
Illustratorでの下準備
テキスト以外の情報を排除する
対象のaiファイルを複製します。(このあとデータに変更を加えるため、複製しておいたほうが安心です。)
文字が読み取りやすいよう、文字の背景の柄や装飾はなるべく削除します。

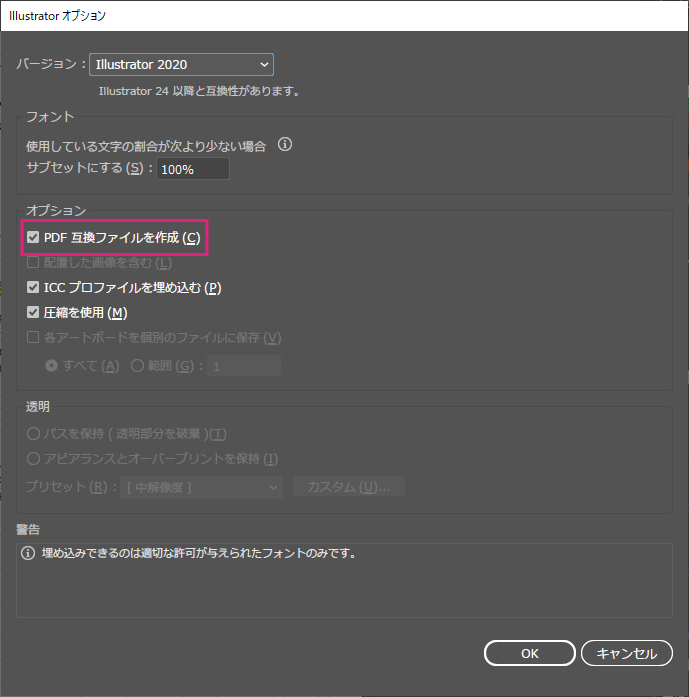
PDF互換ファイルを作成
削除したら、「PDF互換ファイルを作成」にチェックをいれ、aiファイルを一旦保存します。
Adobe Acrobatで開く
そのaiファイルをIllustratorではなく、Adobe Acrobatで開きます。
(aiファイルをAdobe Acrobatを開いたウィンドウへドラッグすると開きます。)
Adobe Acrobatでの作業
「PDFを編集」を選択
Adobe Acrobatのツールバーから「PDFを編集」を選びます。
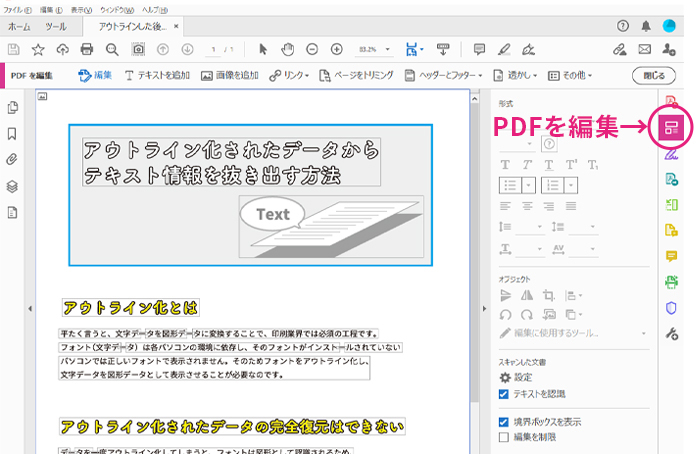
すると自動的にデータにOCR※が適用され、テキストがコピー&ペーストできるような状態になります。
なお、加工した文字や画像上に配置された文字は、OCRが画像として認識するため抜き出せません。

注意点
非常に便利な機能ですが、読み取りに関しては問題もよく起こります。
下の図の場合、一度に読み取れるブロックが小さく、なおかつ「-」が省かれて分割されています。
読み取った文字をコンピューターが自動的に変換するため、変換ミスもよく発生します。

コピー&ペースト後、絶対に一文字抜けている、変換ミスがあるという意識で校正を行うことが必要です。
さいごに
今回はアウトライン化されたデータからできるだけ文字を抜き出す方法をご紹介しました。
アウトライン化されたデータだけではなく、パンフレット等のスキャンデータにもこの方法は使えるので、弊社のエディタースタッフはよく使用しています。
抽出後の校正をしっかり行えば頼れる機能であると思いますので、よろしければお試しください。
この記事を書いた人

- ソリューション事業部 エディター 兼 webディレクター
- 関西の芸術大学で染織・画像編集ソフトを学ぶ。卒業後、県内の織物会社で織物 の製造開発・生産管理・営業を経験する。その後、web制作未経験ながらアーティスへ入社し、webエディターとしてホームページのコンテンツ制作・ディレクションに携わっている。仕事は素早く・丁寧にを心掛けています!
この執筆者の最新記事
- 2025年3月19日WEB【Illustrator】イラレのグラデーションにノイズを加えてみよう!
- 2025年3月19日WEB【Illustrator】イラレのグラデーション機能、基礎を覚えよう!
- 2024年12月23日WEB【Photoshop】アニメーション画像を作ってみよう!(APNG・WebP)【後編・書き出しまで】
- 2024年12月4日WEB【Photoshop】アニメーション画像を作ってみよう!(APNG・WebP)【中編】
関連記事





最新記事





FOLLOW US
最新の情報をお届けします
- facebookでフォロー
- Twitterでフォロー
- Feedlyでフォロー